
The 7 Levels of Software Engineering with AI
I believe there are currently 7 levels of progression when it comes to Software Engineering with AI. In this post, we will explore what they are, and find out where you are!

Software engineering isn’t being replaced, it is both becoming a purer form of what it always was, and something entirely different to what it has been.
As of early 2026, I have observed a natural progression in how we work with AI. It is an evolution of maturity: moving from AI as a better “search engine” to AI as a self-correcting industrial system. But there is a cliff edge ahead. If you are clinging to Level 0-2 by 2028, you will be professionally irrelevant. Stubbornly clinging to hand-crafted syntax today is as futile as the Luddites destroying knitting frames in 1811. You may be a skilled artisan, but your hobby has no place in a professional production line that requires a scale, speed, and quality you simply cannot match manually.
Why? Because the technical friction and cost of construction, bringing an idea to code, has evaporated and is fast approaching zero.
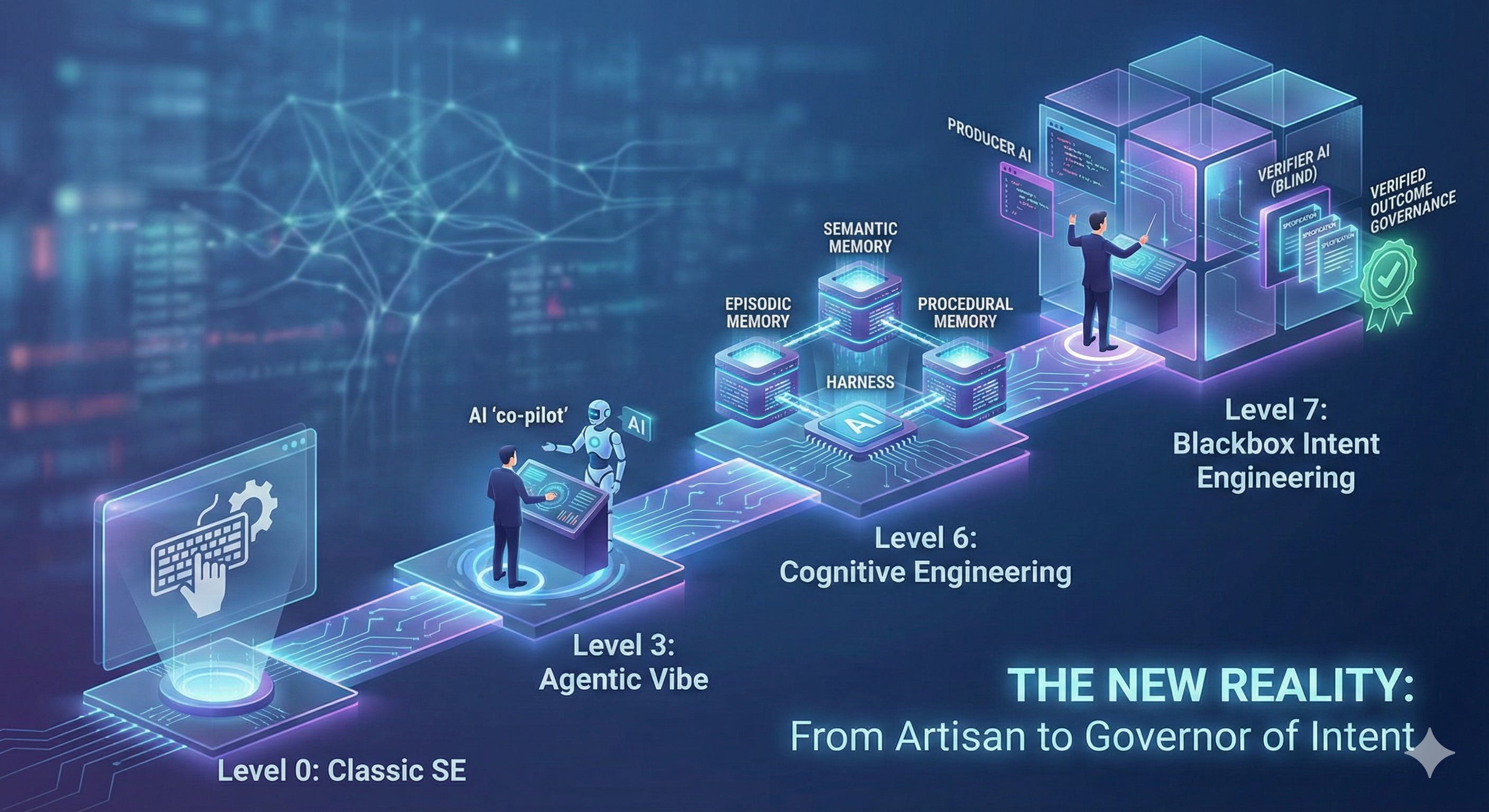
Level 0: Classic software engineering
Self-explanatory: you are not using AI. You are using your IDE like it’s January 2021, relying on dumb-autocompletion, refactoring tools and symbol navigation.
In 2026, this is the equivalent of trying to solve the western housing crisis by building log cabins equipped with only a saw and the power of your muscles: you’ll probably produce something small and beautiful, but by comparison, you’re not making a dent into the underlying problem.
Doing this is fine, if you enjoy the tactile experience of typing out code as a hobby, but it’s best to acknowledge what it is.
Level 1: Assisted software engineering
This is where we all started sometime in the second half of 2021 or early 2022: when Github Copilot first came out, it was an auto-complete on steroids. Copy-pasting from asking ChatGPT questions was also a revelation in terms of having a better, compressed, but sometimes hallucinating search over StackOverflow. Where you could get blocked for days working a problem before 2021, all of a sudden, you had the power at your disposal to, mostly, get unstuck after a few rounds of asking.
Level 2: Integrated assisted software engineering
Eventually, Copilot and other tools evolved to the point where you got a chat-bar in your IDE. You could give the chat a set of files as context, ask questions or request solutions, that you had the option of merging into your selected files.
It seems a long time ago when this was the state-of-the-art, if you think second half of 2024 was a long time ago! It just goes to show how quickly things evolve, when the approaches we used 18 months ago already feel ancient.
Level 3: Agentic vibe coding
Vibe coding in agent-mode is probably where most of the industry sits today in terms of Software Engineering AI maturity: you have either “agent-mode” turned on in Github Copilot in your IDE, or you’ve started using Claude Code, or some other CLI based tool.
At this level, it’s possible to ask your tool harder questions, or complete harder problems, often with context, but even with incomplete context (in terms of files), the agent will find a way to make at least a competent attempt at solving the problem you have asked it to solve.
The issue at level 3 is, that quite often the guardrails and specifications for what you want to achieve are insufficient for your AI assistant to fully complete, or complete without issues. Another problem is that you often have to re-explain yourself to your assistant when you start a new session, causing unnecessary waste of time in repeating yourself.
This often leads to the realization that we need level 4…
Level 4: Structured vibe coding
The first step to moving beyond vibe coding is the realization you need a bit more structure to the process than simply “talking” to the agent and incrementally correct it, reduce ambiguity.
This is usually when you:
Start writing instructions to your agent in things like the CLAUDE.md file.
Start writing down tasks and requirements for your assistant, perhaps even using the agent as an assistant to drive out ambiguity and refine the requirements.
Ask the assistant to write a markdown file keeping track of learnings, what we want to do, what we have done etc. A “Save game” of sorts, to borrow video game terminology.
Perhaps have the assistant generate some architectural documentation as well, speeding up “relearning” between sessions.
Somewhere at level 3 or 4, you might also find yourself, depending on the task at hand, reviewing code more than actively participating in writing.
Level 5: The Manager of Agents
Some of the structure we are starting to adopt at level 4 quickly leads to the realization that many of the tasks are predictable- and/or repetitive.
This naturally leads into starting to define tasks and agents for the work that you can foresee.
All that documentation needs to be kept up-to-date. It makes sense to have a documentation expert agent, and perhaps a skill to invoke with a default template.
Requirements refinement? A domain expert BA sub-agent persona, who thoroughly analyzes and audits requirements, as well as their consistency with prior requirements, calling out any conflicts.
Security experts, DevOps engineer, depending on the project, use your imagination. Just a word of caution: perhaps don’t replicate full Taylorism, have agents and skills that make sense. But if you valued TDD prior to 2025, probably having a “Test agent” doesn’t make sense, make your agent write its own unit tests.
Level 6: Cognitive Engineering
The increased structure of starting to define tasks and agent roles often leads to the next “aha”-moment:
Our job as software engineers, as far as producing the actual software, has evolved from writing code and tests, to defining a harness for our agents, consisting of:
The big picture “North Star” problem and domain we are solving for.
The architectural vision and how it links to the North Star.
Principles of engineering, patterns and architecture we want to follow.
Constraints, non-functional requirements and “Do not”-rules.
Unambiguous, internally consistent requirements, which can be directly translated to code.
However, the big structural challenge when reaching this level is, how do we organize this harness of constraints and knowledge in such a way, that loss of context between sessions and context-compactions is minimal, even when working on large tasks?
Answering this question requires us to become structured, such that we can store all this information in-repository in a way that makes it amenable for recall. The best analogy I currently use for this is mimicking human long-term memory, which is divided into three key parts:
Episodic memory: how we remember what happened, when, and in which order things happened.
Semantic memory: General knowledge, concepts and facts we’ve learned through the work.
Procedural memory: how we know how to perform tasks and processes almost unconsciously.
Thinking of the problem in this way, means we have to get structured about how we store, interlink and shape all the different types of documents in our repository. We are no longer writing code or even directly working on the software we are producing, we are meta-engineering the long-term memory and brain of a team of agents.
As your confidence grows at this level, and you have found a system that works for the domain, you might find yourself spending less and less time reviewing the code that is being produced, because you trust it.
Level 7: Blackbox Intent Engineering
At this point, we have built skills, teams of sub-agents, we have engineered long-term memory and context for our agents, and if we’ve done it well, we are starting to note that the code mostly “just works”, even for large sets of features.
We have firmly shifted the bottleneck of software production from creation to review & verification. We might have some level of trust in the code, as well as the unit- and integration-tests that our agents are producing, but how can we be absolutely sure it works as intended under all circumstances without human inspection and testing?
Turns out we can borrow inspiration from existing disciplines, on how ML- and AI systems are traditionally trained, and formal verification:
We split the agentic system, into two parts: The Producer and The Verifier. The Verifier is intentionally “blind” to the source code. It only sees your high-level intent. Your job as the engineer is to define the Formal Specification that the Verifier uses to hunt for failures:
Scenarios: The “Happy Path” and edge-case journeys the system must survive.
Properties: Behavioural contracts, which should hold under all circumstances, for instance “each processed payment should produce an ‘Invoice Generated’ event”.
Invariants: Systemic truths that can never be violated, for instance ”The sum of all allocated stock must never exceed the physical warehouse capacity”.
Equipped with these, you can then setup your second agentic system (without access to code, but access to system and tools to exercise the system), to create agentic loops which obviously verify that the happy path system works, but also create “Red Team” adversarial loops which try to break the system, both from a specification, as well as performance and security perspective.
By splitting the production from verification, you have also done away with one of the biggest weaknesses of AI aided development over recent years: the propensity of coding agents to write tests that pass, either by undermining functionality or testing.
When the Producer writes code that passes the Verifier swarms adversarial stress tests, you no longer need to read the code. You have empirical proof of correctness.
The New reality of Software Engineering

Many teams have hit a ceiling at Level 3, this is the current mainstream “state-of-the-art” of the industry. But it is far below what is practically possible, as of now.
Software production has been democratized, made possible, much like photography was democratized by digital cameras. This didn’t mean that photographers went extinct though. The same is true of Software Engineering, we are evolving from multi-functional artisans of code, to meta-enginers of systems of agents, memory and intent. The work we used to do at Level 0, will now shift to being done mostly at mutually inclusive and complementary Levels 5 to 7.
In a sense, our job has now finally become what we were always meant to do: Solve problems at the intersection of business, humans, and technology, not just writing syntax.
I will come back later with posts and guides specifically on Levels 6 and 7, if you want to read these, please subscribe!
This is very true, I notice the difference between engineers now is how well they have learned to use AI as a tool.
I would say when approaching new projects, spending time defining rules, context, testing and splitting the work becomes more important than dividing straight in.
I’m getting increasingly frustrated with those who vibe code and when you ask for an explanation of that they have built their response is “let me ask AI”. If you do not understand what you are building then you are setting yourself up for failure.